CS/IT Gate Yearwise
CS/IT Gate 2026 (Set 2)
CS/IT Gate 2025 (Set 1)
CS/IT Gate 2025 (Set 2)
CS/IT Gate 2024 (Set 1)
CS/IT Gate 2024 (Set 2)
CS/IT Gate 2023
CS/IT Gate 2022
CS/IT Gate 2021 (Set 1)
CS/IT Gate 2021 (Set 2)
CS/IT Gate 2020
CS/IT Gate 2019
CS/IT Gate 2018
CS/IT Gate 2017 (Set 1)
CS/IT Gate 2017 (Set 2)
CS/IT Gate 2016 (Set 1)
CS/IT Gate 2016 (Set 2)
CS/IT Gate 2015 (Set 1)
CS/IT Gate 2015 (Set 2)
CS/IT Gate 2015 (Set 3)
CS/IT Gate 2014 (Set 1)
CS/IT Gate 2014 (Set 2)
CS/IT Gate 2014 (Set 3)
CS and IT Gate 2026 Set-2 Questions with Answer
Ques 40 GATE 2026 SET-2
Consider a stack 𝑆 and a queue 𝑄. Both of them are initially empty and have the
capacity to store ten elements each. The elements 1,2,3,4, and 5 arrive one by one,
in that order. When an element arrives, it is assigned either to 𝑆 (pushed on 𝑆 ) or
to 𝑄 (enqueued to 𝑄). Once all the five elements are stored, the output is generated
in two steps. First, stack S is emptied by popping all elements.
Then queue 𝑄 is
emptied by dequeueing all elements. The output obtained by following this process
is 4 3 1 2 5 .
Given the output, the objective is to predict whether an element was assigned to 𝑆
or 𝑄.
Which of the following options is/are possible valid assignment(s) of the
elements?
Note: In the options, the notation 𝑥𝑆 denotes that element 𝑥 was assigned to 𝑆 and
y𝑄 denotes that element 𝑦 was assigned to 𝑄.
The output is 4 3 1 2 5. Stack S is emptied first by popping (LIFO), then Queue Q is emptied by dequeueing (FIFO). So whatever comes out of S appears at the front of the output, and whatever comes out of Q follows at the end.
Option A — 1S, 2Q, 3S, 4S, 5Q
S gets 1, 3, 4 in that order. Popping gives 4, 3, 1. Q gets 2, 5. Dequeueing gives 2, 5. Full output: 4 3 1 2 5 ✓
Option B — 1Q, 2Q, 3S, 4S, 5Q
S gets 3, 4. Popping gives 4, 3. Q gets 1, 2, 5. Dequeueing gives 1, 2, 5. Full output: 4 3 1 2 5 ✓
Option C — 1Q, 2Q, 3Q, 4S, 5S
S gets 4, 5. Popping gives 5, 4. But output starts with 4 3, not 5 4. ✗
Option D — 1S, 2S, 3S, 4Q, 5Q
S gets 1, 2, 3. Popping gives 3, 2, 1. But output starts with 4 3, not 3 2. ✗
Correct answer: A and B ✓
Ques 41 GATE 2026 SET-2
Consider three processes P1, P2, and P3 running identical code, as shown in the
pseudocode below. A and B are two binary semaphores initialized to 1 and 0,
respectively. X is a shared variable initialized to 0. Each line in the pseudocode is
executed atomically.
Pseudocode of P1, P2, and P3

Which of the following patterns is/are possible to be generated as an outcome of the execution of these three processes?
All three processes run the same code. A = 1, B = 0, X = 0 initially.
How it flows
Only one process can pass Wait(A) at a time since A is binary. The 1st process prints , makes X = 1, skips the if-block, calls Signal(A), then blocks at Wait(B) since B = 0.
The 2nd process prints , makes X = 2, enters the if-block, prints $, calls Signal(B) which unblocks the 1st process, then calls Signal(A).
The 1st process now prints # and calls Signal(B). The 3rd process prints *, makes X = 3, skips the if-block, then waits on B and eventually prints #.
Why D is impossible
D requires three * prints before .Butthe3rdprocesscannotenteruntilthe2ndcallsSignal(A),whichhappensonlyafter. But the 3rd process cannot enter until the 2nd calls Signal(A), which happens only after
.Butthe3rdprocesscannotenteruntilthe2ndcallsSignal(A),whichhappensonlyafter is already printed. So ***$ can never happen.
Why A, B, C are possible
The 3rd process's * can appear before the first #, between the two # prints, or after both — depending on scheduling. All three give valid distinct patterns, making A, B, and C all possible.
Correct answer: A, B, C ✓
Ques 42 GATE 2026 SET-2
Consider a system with a processor and a 4 KB direct mapped cache with block size
of 16 bytes. The system has a 16 MB physical memory. Four words P, Q, R, and S
are accessed by the processor in the same order 10 times. That is, there are a total
of 40 memory references in the sequence P, Q, R, S, P, Q, R, S,…
Assume that the cache memory is initially empty. The physical addresses of the
words are given below (1 word =1 byte).
P: 0x845B32, Q: 0x845B26, R: 0x845B36, S: 0x846B32
Which of the following statements is/are true?
Note: 1K=210 and 1M=220
The correct answers are Option A and Option B.
Cache configuration: Cache = 4 KB, block size = 16 bytes → 256 cache lines. Address split: [Tag: 12 bits | Index: 8 bits | Offset: 4 bits]. Cache line = lower 8 bits of block address = floor(address / 16) mod 256.
Cache line mapping: P (0x845B32) → block 0x845B3 → line 179. Q (0x845B26) → block 0x845B2 → line 178. R (0x845B36) → block 0x845B3 → line 179 (same block as P). S (0x846B32) → block 0x846B3 → line 179 (same line as P and R, different block).
Access trace — Round 1 (P→Q→R→S): P hits empty cache → MISS, loads block 0x845B3 into line 179. Q hits empty line 178 → MISS, loads block 0x845B2. R checks line 179 which has P's block → HIT. S checks line 179 which has P's block, tag mismatch → MISS, evicts P/R's block, loads block 0x846B3.
Round 2+ onwards: P checks line 179 which has S's block → MISS, loads block 0x845B3 back. Q checks line 178 still intact → HIT. R checks line 179 which just loaded P's block → HIT. S checks line 179 which has P's block → MISS again.
Option A — Every access to P is a miss: P always finds S's block in line 179 → TRUE. Correct.
Option B — Every access to R is a hit: R always finds P's freshly loaded block in line 179 → TRUE. Correct.
Option C — Every access to Q is a miss: Q misses only on first access; all subsequent accesses hit since nothing evicts line 178 → FALSE. Incorrect.
Option D — All accesses to S after the first result in hits: P evicts S's block every round before S is accessed again → S always misses → FALSE. Incorrect.
Ques 43 GATE 2026 SET-2
To keep track of free blocks in a file system, one of the two approaches is generally used – using bitmaps (bit vectors) or using linked lists. Consider that the linked list approach is used to keep track of free blocks in a file system. Assume that the disk size is 16 GB, block size is 2 KB, and block numbers used are 32-bit long. A single pointer of size 4 bytes is used in each block of the list to point to the next block of the list. The number of blocks required to hold the free disk block numbers is ____________. (answer in integer) Note: 1K=210 and 1G=230
The correct answer is 16,384.
Total disk blocks: Disk size = 16 GB = 234 bytes. Block size = 2 KB = 211 bytes. Total blocks = 234 / 211 = 223 = 8,388,608 blocks.
Entries per list block: Each list block = 2048 bytes. Each block number = 4 bytes. One pointer (4 bytes) per list block points to the next list block. Usable entries per list block = (2048 − 4) / 4 = 2044 / 4 = 511 block numbers.
Number of list blocks needed: = ceil(223 / 511) = ceil(16,416.06) = 16,417 blocks.
If the pointer is assumed to not reduce usable entries (a simpler interpretation): entries per block = 2048 / 4 = 512, and blocks needed = 223 / 29 = 214 = 16,384.
Ques 44 GATE 2026 SET-2
A system has a Translation Lookaside Buffer (TLB) that has a reach of 1 MB. TLB reach is defined as the total amount of physical memory that can be accessed through the TLB entries. The paging system uses pages of size 4 KB. The virtual address space is 64 GB and physical address space is 1 GB. If each TLB entry stores a 4-bit process id, page number, frame number, and a 2-bit control field, then the size of the TLB (in bytes) is ___________. (answer in integer) Note: 1K=210, 1M=220, 1G=230
The correct answer is 1536 bytes
Number of TLB entries: TLB reach = entries × page size → 220 = N × 212 → N = 28 = 256 entries.
Page number bits: Virtual address space = 64 GB = 236 bytes. Virtual pages = 236 / 212 = 224. Page number = 24 bits.
Frame number bits: Physical address space = 1 GB = 230 bytes. Physical frames = 230 / 212 = 218. Frame number = 18 bits.
Bits per TLB entry: 4 (process ID) + 24 (page number) + 18 (frame number) + 2 (control) = 48 bits = 6 bytes.
Total TLB size: 256 entries × 6 bytes = 1536 bytes.
Ques 45 GATE 2026 SET-2
Consider contiguous allocation of physical memory to processes using variable partitioning scheme. Suppose there are 8 holes in the memory of sizes 20 KB, 4 KB, 25 KB, 18 KB, 7 KB, 9 KB, 15 KB, and 12 KB. Assume that no two holes are adjacent. Two processes P1 of size 16 KB and P2 of size 9 KB arrive in that order, and they are allocated memory using the best-fit technique. After allocating space to P1 and P2, the number of holes of size less than 8 KB is ____________. (answer in integer) Note: 1K=210
The correct answer is 3.
Initial holes: 20, 4, 25, 18, 7, 9, 15, 12 KB.
Allocating P1 (16 KB) using best-fit: Holes large enough: 20, 25, 18 KB. Smallest sufficient = 18 KB. Remainder = 18 − 16 = 2 KB. Holes become: 20, 4, 25, 2, 7, 9, 15, 12 KB.
Allocating P2 (9 KB) using best-fit: Holes large enough: 20, 25, 9, 15, 12 KB. Smallest sufficient = 9 KB (exact fit, no remainder). The 9 KB hole is fully consumed. Holes become: 20, 4, 25, 2, 7, 15, 12 KB.
Holes with size less than 8 KB: 4, 2, 7 KB → 3 holes
Ques 46 GATE 2026 SET-2
Consider a system with 1 MB physical memory and a word length of 1 byte. The system uses a direct mapped cache, with block numbers starting from 0. The word with physical address 0xA2C28 is mapped to the cache block number 17610. The maximum possible size of the cache (in KB) for this configuration is ___________. (answer in integer) Note: 1K=210 and 1M=220
The correct answer is 128 KB
Address in binary: 0xA2C28 = 1010 0010 1100 0010 1000 (20 bits). The address is split into a Line/Index field (LO) and a Word Offset (WO).
Word Offset: The lower 6 bits (101000) represent the word offset, meaning block size = 26 = 64 bytes.
Line/Index field: The remaining upper bits give the cache line address (LO) = 11 bits, meaning the number of cache lines = 211 = 2048.
Cache size: Cache address = LO + WO = 11 + 6 = 17 bits. Therefore cache size = 217 bytes = 128 KB.
Ques 47 GATE 2026 SET-2
A non-pipelined instruction execution unit that operates at 1.6 GHz clock takes an average of 5 clock cycles to complete the execution of an instruction. To improve the performance, the system was pipelined with a goal of achieving an average throughput of one instruction per clock cycle. However, it could operate only at 1.2 GHz due to pipeline overheads. While executing a program in the pipelined design, 30% of instructions encountered a stall of 2 cycles due to pipeline hazards. The speed-up obtained by the pipelined design over the non-pipelined one for this program is ___________. (rounded off to two decimal places) Note: 1G=109
The correct answer is 2.34.
Non-pipelined time per instruction: Clock period = 1 / 1.6 GHz = 0.625 ns. Time per instruction = 5 cycles × 0.625 ns = 3.125 ns.
Pipelined CPI with hazard stalls: Ideal pipelined CPI = 1. Stall penalty per instruction = 30% × 2 stall cycles = 0.6 cycles. Effective pipelined CPI = 1 + 0.6 = 1.6 cycles.
Pipelined time per instruction: Clock period = 1 / 1.2 GHz = 0.833 ns. Time per instruction = 1.6 × 0.833 ns = 1.333 ns.
Speed-up: Speed-up = Non-pipelined time / Pipelined time = 3.125 / 1.333 = 2.34.
Ques 48 GATE 2026 SET-2
Consider a new TCP connection between a sender and a receiver. The receiver advertised window is constant at 48 KB, the maximum segment size (MSS) is 2 KB, and the slow start threshold for TCP congestion control is 16 KB. Assume that there are no timeouts or duplicate acknowledgements. The number of rounds of transmission required for the congestion control algorithm of the TCP connection to reach the congestion avoidance phase is ___________. (answer in integer) Note: 1K=210
The correct answer is 4
Given: Receiver window = 48 KB, MSS = 2 KB, ssthresh = 16 KB = 8 MSS. TCP starts with cwnd = 1 MSS = 2 KB and grows exponentially in slow start.
Round-by-round progression:
Round 1: cwnd = 1 MSS = 2 KB - Slow Start
Round 2: cwnd = 2 MSS = 4 KB - Slow Start
Round 3: cwnd = 4 MSS = 8 KB - Slow Start
Round 4: cwnd = 8 MSS = 16 KB - Slow Start ends; cwnd has reached ssthresh
Round 5: cwnd = 9 MSS = 18 KB - Congestion Avoidance begins here
The congestion avoidance phase is reached after 4 rounds of transmission. The receiver window of 48 KB is not a limiting factor since cwnd is well below it throughout.
Ques 49 GATE 2026 SET-2
Consider the digital circuit shown below with two input lines A and B, two select
lines S0 and S1, and an output line Y. The blocks Q and M represent active high
2:4 decoder and 4-to-1 multiplexer, respectively. Out of 16 possible input
combinations, the number of combinations that produce Y=1 is ____________.
(answer in integer)
Note: One input combination is an instance of [A B S1 S0].
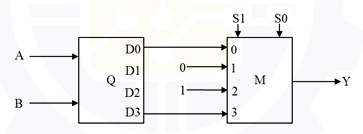
he correct answer is 6.
The circuit consists of a 2×4 decoder (inputs A, B) feeding a 4-to-1 multiplexer M with select lines S1 and S0. The MUX data inputs are wired as: I0 = AB̄, I1 = AB̄ (or tied), I2 = 1 (always high), I3 = AB.
Case 1 - S1S0 = 10 (selects I2 = 1): Output y = 1 regardless of A and B. Since A and B can each be 0 or 1 independently, this gives 4 combinations: (0,0,1,0), (0,1,1,0), (1,0,1,0), (1,1,1,0).
Case 2 - S1S0 = 00 (selects I0 = AB̄): Output y = 1 only when AB̄ = 1, i.e., A=0, B=0. This gives 1 combination: (0,0,0,0).
Case 3 - S1S0 = 11 (selects I3 = AB): Output y = 1 only when AB = 1, i.e., A=1, B=1. This gives 1 combination: (1,1,1,1).
Case 4 - S1S0 = 01 (selects I1): The MUX input I1 corresponds to the decoder output D1 = AB̄ (which is 0 for all A,B combinations in standard 2×4 decoder with active-high outputs where only one line is high). y = 0 for all A,B. 0 combinations.
Total combinations = 4 + 1 + 1 = 6.
Ques 50 GATE 2026 SET-2
Consider the following ANSI-C program.

Note: Assume that the program compiles and runs successfully.
Explanation:
1. int *ptr, a, b, c; (Declares variables)
2. a=5; b=11; c=20; (Initial values set)
3. ptr=&a; (ptr points to a)
4. *ptr=c; (Value of a becomes equal to c, so a = 20)
5. ptr=&c; (ptr now points to c)
6. a=*(&b); (Value of a becomes equal to b, so a = 11)
7. c=*ptr-a; (Since ptr points to c, *ptr is 20. Thus, c = 20 - 11 = 9)
8. printf("%d",c); (Outputs 9)
Ques 51 GATE 2026 SET-2
Consider the following ANSI-C function.

Note: Ignore syntax errors (if any) in the function.
The correct answer is 1.
The function computes a value based on the length = end + 1 - start of an interval, and recurses in three ways depending on length % 3. Crucially, only one branch ever adds to the return value:
length % 3 == 0: returns func(start+1, end) → length decreases by 1, new length % 3 == 2. No value added.
length % 3 == 2: returns func(start+2, end) → length decreases by 2, new length % 3 == 0. No value added.
length % 3 == 1: returns 1 + func(start, end-1) → length decreases by 1, new length % 3 == 0. +1 added here.
Why the maximum is 1: Once length % 3 == 1 fires and adds 1, the new length has remainder 0. The chain then alternates: mod 0 → mod 2 → mod 0 → mod 2 → ... until length drops below 1 and returns 0. The remainder never returns to 1 after the first firing. Therefore, no matter what valid starting values of start and end are chosen, the function can add 1 at most once throughout the entire recursive chain.
Example trace — func(0, 3), length = 4 (mod 1): 1 + func(0,2) → length=3(mod 0) → func(1,2) → length=2(mod 2) → func(3,2) → length=0 → return 0. Total = 1.
The correct maximum value that can be returned is 1.
Ques 52 GATE 2026 SET-2
The determinant of a 4×4 matrix A is 3. The value of the determinant of 2A is ____________. (answer in integer)
The correct answer is 48.
For any n×n matrix A, scaling the matrix by a scalar k scales the determinant by kⁿ. This is because each row of the matrix gets multiplied by k, and there are n rows - each contributing a factor of k to the determinant.
Formula: det(kA) = kⁿ · det(A)
Here, the matrix is 4×4 (n = 4), the scalar is k = 2, and det(A) = 3. Applying the formula:
det(2A) = 2⁴ × 3 = 16 × 3 = 48.
Why kⁿ and not just k? The determinant is a multilinear function of the rows (or columns). Multiplying the entire matrix by k multiplies every one of the n rows by k, so the determinant picks up a factor of k exactly n times - giving kⁿ, not k.
A common mistake is to compute 2 × 3 = 6 (forgetting the matrix dimension) or 2³ × 3 = 24 (using n−1). Always use the full dimension n in the formula.

Total Unique Visitors