CS/IT Gate Yearwise
CS/IT Gate 2026 (Set 2)
CS/IT Gate 2025 (Set 1)
CS/IT Gate 2025 (Set 2)
CS/IT Gate 2024 (Set 1)
CS/IT Gate 2024 (Set 2)
CS/IT Gate 2023
CS/IT Gate 2022
CS/IT Gate 2021 (Set 1)
CS/IT Gate 2021 (Set 2)
CS/IT Gate 2020
CS/IT Gate 2019
CS/IT Gate 2018
CS/IT Gate 2017 (Set 1)
CS/IT Gate 2017 (Set 2)
CS/IT Gate 2016 (Set 1)
CS/IT Gate 2016 (Set 2)
CS/IT Gate 2015 (Set 1)
CS/IT Gate 2015 (Set 2)
CS/IT Gate 2015 (Set 3)
CS/IT Gate 2014 (Set 1)
CS/IT Gate 2014 (Set 2)
CS/IT Gate 2014 (Set 3)
CS and IT Gate 2026 Set-2 Questions with Answer
Ques 1 GATE 2026 SET-2
For two different persons x and y, the predicate M(x, y) denotes that x knows y. Consider the following statement.
There is a person who does not know anyone else, but that person is known by everyone else.
Which one of the following expressions represents the above statement?
The English statement has two parts about the same special person y — they do not know anyone else, but everyone else knows them.
The first word "there is" tells us we need an existential quantifier for y, so we start with ∃y. The phrases "anyone else" and "everyone else" both refer to all persons x different from y, so we need ∀x with the condition x ≠ y. Using implication (x ≠ y) → ... is the standard way to restrict the universal quantifier to only those x that are different from y.
Inside the implication we need two things to hold simultaneously for every such x — M(x, y) meaning x knows y (everyone else knows that person), and ¬M(y, x) meaning y does not know x (that person does not know anyone else). Both conditions are joined with ∧.
So the full expression is (∃y)(∀x)((x ≠ y) → (M(x, y) ∧ ¬M(y, x))), which is option A.
Why the others are wrong:
Option B uses ∀y∃x which says "for every person y, there exists some x" — this changes the meaning completely and does not fix one special person.
Option C uses ∃y∃x which says there exist some y and some x — this only claims two specific people have this relationship, not that it holds for all others.
Option D uses ∀y∀x which universalises over everyone — this would mean every person simultaneously does not know anyone and is known by everyone, which is far too strong and not what is stated.
Correct answer: A ✓
Ques 2 GATE 2026 SET-2
The set T represents various traversals over binary tree. The set S represents the order of visiting nodes during a traversal.

Which one of the following is the correct match from T to S?
To find the correct match, we need to recall the standard definitions of the three primary depth-first binary tree traversals: Inorder, Preorder, and Postorder.
I: Inorder Traversal (Matches L)
In an inorder traversal, the algorithm recursively visits the left subtree, then processes the root node, and finally recursively visits the right subtree. Therefore, I correctly matches L (left subtree, node, right subtree).
II: Preorder Traversal (Matches M)
In a preorder traversal, the algorithm processes the root node first, before moving on to recursively visit the left subtree, and finally the right subtree. Therefore, II correctly matches M (node, left subtree, right subtree).
III: Postorder Traversal (Matches N)
In a postorder traversal, the algorithm recursively visits the left subtree, then recursively visits the right subtree, and processes the root node at the very end. Therefore, III correctly matches N (left subtree, right subtree, node).
Correct Match: I-L, II-M, III-N ✓
Ques 3 GATE 2026 SET-2
Which one of the following statements is equivalent to the following assertion? Turing machine M decides the language L ⊆ {0,1}*.
A Turing machine that decides a language is called a decider. The key difference between a decider and a recognizer is that a decider must always halt — it cannot loop forever on any input. It must give a definitive yes or no answer for every string it receives.
Option A — M halts on all inputs in {0,1}*
Halting on every input is a property of a decider, but halting alone is not enough. A machine could halt on every input and still give wrong answers — accepting strings it should reject or rejecting strings it should accept. So A is a necessary condition but not sufficient to define deciding. A is wrong.
Option B — M accepts all strings in L
This describes a Turing machine recognizer, also called a semi-decider. A recognizer accepts every string in L but may loop forever on strings not in L. It never has to reject — it can just run infinitely. This is weaker than deciding. B is wrong.
Option C — M rejects all strings in {0,1}* − L
This is the mirror image of B. It only covers what happens to strings outside L and says nothing about what happens to strings inside L. A machine could reject everything including valid strings in L and still satisfy C. C is wrong.
Option D — M accepts all strings in L and rejects all strings in {0,1}* − L
This is the complete and exact formal definition of a decider. For every string in the universe {0,1}*, M must halt and give the correct answer. Strings in L get accepted, strings outside L get rejected. No looping is allowed anywhere. This perfectly captures what it means to decide a language.
The word "decides" in formal language theory always means the machine is a total function over all inputs — correct acceptance for members, correct rejection for non-members, and guaranteed termination in both cases.
Correct answer: D ✓
Ques 4 GATE 2026 SET-2
The probability density function f(x) of a random variable X which takes real values is
f(x) = 1/(3√(2π)) exp(-x²/18), x ∈ (-∞, +∞)
Which one of the following statements is correct about the random variable?
The given function is f(x) = 1/3√(2π) × exp(−x2/18), defined over (−∞, +∞).
The standard Normal distribution has the form 1/σ√(2π) × exp(−(x−μ)2/2σ2). Comparing with the given function, the denominator outside is 3√(2π) so σ = 3, and inside the exponential the denominator is 18 = 2 × 9 = 2σ2, confirming σ = 3. Since there is no shift in x, μ = 0.
The given f(x) matches exactly a Normal distribution N(0, 9) with mean μ = 0 and variance σ2 = 9.
The other options don''t fit — exponential distributions are only defined for x ≥ 0, Poisson is discrete, and uniform has a constant value over a bounded interval. None of these match the bell-curve form over (−∞, +∞).
Correct answer: B — X is a Normal random variable with μ = 0 and σ2 = 9 ✓
Ques 5 GATE 2026 SET-2
In the context of DBMS, consider the two sets T and S given below.
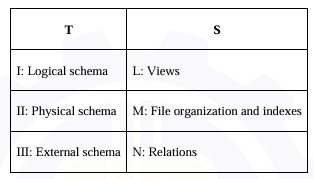
Which one of the following is the correct match from T to S?
I: Logical schema → N: Relations
The logical schema describes the overall structure of the database in terms of relations (tables), attributes, constraints and their relationships. It is what the DBA sees and works with. Relations belong to the logical level.
II: Physical schema → M: File organization and indexes
The physical schema describes how data is actually stored on disk — file organization, indexing structures, access paths, storage details. This is the lowest level dealing with physical storage.
III: External schema → L: Views
The external schema (also called user views or subschema) defines how different users or applications see the data. Each user gets a customized view — hiding parts of the logical schema they don''t need. Views belong to the external level.
So the correct mapping is I-N, II-M, III-L → Option C.
Ques 6 GATE 2026 SET-2
Which one of the following options is not a property of Boolean Algebra?
Note: + is OR operation, · is AND operation, and ' is NOT operation
The correct answer is Option B — a · a'' = 1, which is NOT a property of Boolean Algebra.
Option A — a + b = b + a: This is the Commutative Law for the OR operation — the order of operands does not affect the result. This is a valid Boolean Algebra property. Is a property.
Option B — a · a'' = 1: This is incorrect. The correct Complement Law for AND states that a · a'' = 0 — any variable ANDed with its own complement always equals 0, because one of them must be 0 and 0 AND anything = 0. The value 1 would require both a and a'' to be 1 simultaneously, which is impossible. NOT a property — Correct answer.
Option C — a + a'' = 1: This is the Complement Law for OR — any variable ORed with its complement always equals 1, since one of them must be 1. This is a valid Boolean Algebra property. Is a property.
Option D — a × b = b · a: Both × and · represent the AND operation here. This states the Commutative Law for AND — order of operands does not matter. This is a valid Boolean Algebra property. Is a property.
Ques 7 GATE 2026 SET-2
In C runtime environment, which one of the following is stored in heap?
The correct answer is Option C — A dynamically allocated array of integers created using malloc().
The C runtime memory layout is divided into distinct regions. The stack holds local variables, function parameters, and return addresses — all with automatic lifetime tied to their scope. The BSS/data segment holds global and static variables. The heap is the region explicitly managed by the programmer for dynamic memory allocation.
Option A — Static variable inside a function: The static keyword gives a variable static storage duration regardless of where it is declared. It is stored in the BSS or data segment, persisting for the entire program lifetime. Not heap.
Option B — Array declared inside a function: A locally declared array like int arr[10] inside a function is a local variable with automatic storage duration — it lives on the stack and is destroyed when the function returns. Not heap.
Option C — Dynamically allocated array via malloc(): malloc() explicitly requests memory from the heap at runtime. The programmer is responsible for freeing it using free(). This is the canonical use of heap memory. Heap ✓ Correct.
Option D — Return address of a function: When a function is called, the CPU pushes the return address onto the call stack so execution can resume at the correct point after the function completes. Not heap.
Ques 8 GATE 2026 SET-2
Consider the following two statements about interrupt handling mechanisms in a CPU.
S1: In non-vectored interrupt mechanism, it usually takes more time to start the Interrupt Service Routine (ISR) when compared to that in a vectored interrupt mechanism.
S2: In daisy-chain interrupt mechanism, the CPU polls all the input devices individually to determine the source of the interrupt.
Which one of the following options is correct with respect to S1 and S2?
The correct answer is Option C — S1 is true and S2 is false.
S1 — Non-vectored vs vectored interrupt latency: In a vectored interrupt, the interrupting device directly supplies the starting address of its ISR to the CPU upon acknowledgement, so the CPU jumps to the correct handler immediately. In a non-vectored interrupt, all interrupts redirect to a single fixed address, and the ISR must then identify the source — typically by polling status registers — before branching to the correct handler. This identification overhead means non-vectored interrupts take more time to start the actual ISR. S1 is TRUE.
S2 — Daisy-chain mechanism: In daisy-chain interrupt handling, devices are connected in a hardware priority chain. When the CPU issues an interrupt-acknowledge signal, it propagates down the chain and is intercepted by the highest-priority device that raised the interrupt. That device then places its vector (device ID or ISR address) on the data bus — the CPU does not poll devices individually. Polling is a separate, software-based mechanism where the CPU explicitly checks each device one by one. Daisy-chaining is entirely hardware-driven. S2 is FALSE.
Ques 9 GATE 2026 SET-2
Consider the following three ANSI-C programs, P1, P2 and P3
Which one of the following statements is true?

P1 declares a as a global variable and then declares another a as a local variable inside main. In C, a local variable is allowed to have the same name as a global variable. The local one simply shadows the global within that scope. This is perfectly valid ANSI-C and P1 compiles cleanly.
P2 declares int a = 5 and then immediately declares int a = 7 again inside the same function scope. Redeclaring the same variable name within the same scope is not allowed in ANSI-C, so P2 fails to compile.
P3 does the same thing but with a different type — first int a = 5 then float a = 7 in the same scope. Changing the type does not help. ANSI-C still treats this as a redeclaration error in the same scope, so P3 also fails to compile.
The key rule here is that variable shadowing across scopes (global vs local) is allowed, but redeclaration within the same scope is never allowed, regardless of whether the type changes or not.
Correct answer: A — Only P1 compiles without error ✓
Ques 10 GATE 2026 SET-2
Consider concurrent execution of two transactions T1 and T2 in a DBMS, both of which access a data object A. For these two transactions to not conflict on A, which one of the following statements must be true?
The correct answer is Option A — Both T1 and T2 only read A.
In database concurrency control, two operations from different transactions on the same data object are said to conflict if and only if at least one of the operations is a Write. This gives three conflicting pairs and one non-conflicting pair on any shared data item A.
The three conflicting pairs are: Read-Write (one transaction reads while the other writes), Write-Read (one writes while the other reads), and Write-Write (both transactions write). In all these cases, the order of execution can affect the final outcome or the value read, which is why they conflict.
The only non-conflicting pair is Read-Read — when both transactions only read A, neither modifies it, so the order of their execution has no effect on the database state or on what either transaction reads. This is Option A.
Option B (T1 reads, T2 writes): A Read-Write conflict — the value T1 reads depends on whether T2''s write happens before or after. Conflict exists. Incorrect.
Option C (T1 writes, T2 reads): A Write-Read conflict — the value T2 reads depends on whether T1''s write has already occurred. Conflict exists. Incorrect.
Option D (Both write): A Write-Write conflict — the final value of A depends on which write happens last. Conflict exists. Incorrect.
The fundamental rule to remember: two reads never conflict; any operation involving a write can conflict with any other operation on the same data item.
Ques 11 GATE 2026 SET-2
Consider a file of size 4 million bytes being transferred between two hosts connected via a path consisting of three consecutive links of bandwidth 2 Mbps, 500 kbps, and 1 Mbps, respectively. ... Which one of the following is the total time (in seconds) to transfer the file?
To find the total time to transfer the file, we must determine the total file size in bits and identify the slowest link in the network path, known as the bottleneck bandwidth.
Calculating the Total File Size
The file size is given as 4 million bytes. Since network transmission speeds are measured in bits per second, we first need to convert bytes to bits (1 byte = 8 bits).
File Size = 4 × 106 bytes = 4 × 106 × 8 bits = 32 × 106 bits.
Identifying the Bottleneck Bandwidth
The network path consists of three consecutive links:
Link 1: 2 Mbps = 2 × 106 bps
Link 2: 500 kbps = 500 × 103 bps = 0.5 × 106 bps
Link 3: 1 Mbps = 1 × 106 bps
In a multi-link network, the overall data transfer rate is always constrained by the slowest link. Comparing the three, the minimum bandwidth is 500 kbps (0.5 × 106 bps).
Calculating the Transfer Time
Because network data is pipelined (sent as a continuous stream of packets) and processing/propagation delays are negligible, the total transfer time is simply the time it takes to push the entire file through that bottleneck link.
Total Time = File Size / Bottleneck Bandwidth
Total Time = (32 × 106 bits) / (0.5 × 106 bps)
Total Time = 32 / 0.5 = 64 seconds.
Correct Answer: B (64) ✓
Ques 12 GATE 2026 SET-2
Which one of the following protocols may need to broadcast some of its messages?
DHCP (Dynamic Host Configuration Protocol) is the protocol that needs to broadcast some of its messages. When a new device joins a network, it does not yet have an IP address and does not know the address of any DHCP server. Because of this, the device sends a DHCP Discover message as a broadcast to the address 255.255.255.255, hoping that a DHCP server on the network will hear it and respond. The server then replies with a DHCP Offer, also typically broadcast, and the process completes with Request and Acknowledgment messages. Without broadcasting, the client would have no way to locate the server since it has no IP configuration at all yet.
The other options do not need broadcasting. SMTP (Simple Mail Transfer Protocol) is used for sending emails between mail servers and clients — it always communicates with a known server address using TCP on port 25. FTP (File Transfer Protocol) transfers files between a client and a known server and always uses directed unicast communication. HTTP (Hypertext Transfer Protocol) is used for web communication between browsers and servers, also always unicast to a specific IP address and port.
The key distinction is that DHCP operates before the client has any IP identity — so broadcasting is not just useful, it is the only option available at that stage.
Correct answer: C — DHCP ✓
Ques 13 GATE 2026 SET-2
Which one of the following CPU scheduling algorithms cannot be preemptive?
The correct answer is Option B — First Come First Serve (FCFS) Scheduling.
A scheduling algorithm is preemptive if the CPU can be forcibly taken away from a running process before it completes. FCFS is the one algorithm in this list that cannot be preemptive — once a process gets the CPU, it holds it until it finishes or voluntarily blocks (e.g., for I/O). There is no mechanism by which a newly arriving process can displace the currently running one.
Option A — SRTF: Shortest Remaining Time First is the preemptive version of Shortest Job First by definition. When a new process arrives with a shorter burst time than the remaining time of the running process, the CPU is immediately preempted. It is always preemptive. Incorrect.
Option B — FCFS: Processes are scheduled strictly in arrival order and always run to completion. No preemption is possible under FCFS — not by design, and not by any variant of it. This is the only algorithm here that cannot be preemptive. Correct.
Option C — Round Robin: Built entirely around preemption — the time quantum is the preemption mechanism. When a process exhausts its time slice, the CPU is forcibly reassigned. Round Robin is always preemptive. Incorrect.
Option D — Priority Scheduling: Can be implemented in both modes. In the preemptive version, a higher-priority process arriving in the ready queue immediately preempts the current process. In the non-preemptive version, the CPU is only reassigned after the current process yields. Since it can be preemptive, it does not satisfy the question. Incorrect.
The key distinction: SRTF and Round Robin are defined by preemption and cannot operate without it. Priority Scheduling is flexible. FCFS is defined by non-preemption and cannot have preemption added without fundamentally changing its nature.

Total Unique Visitors