CS/IT Gate Yearwise
CS/IT Gate 2026 (Set 2)
CS/IT Gate 2025 (Set 1)
CS/IT Gate 2025 (Set 2)
CS/IT Gate 2024 (Set 1)
CS/IT Gate 2024 (Set 2)
CS/IT Gate 2023
CS/IT Gate 2022
CS/IT Gate 2021 (Set 1)
CS/IT Gate 2021 (Set 2)
CS/IT Gate 2020
CS/IT Gate 2019
CS/IT Gate 2018
CS/IT Gate 2017 (Set 1)
CS/IT Gate 2017 (Set 2)
CS/IT Gate 2016 (Set 1)
CS/IT Gate 2016 (Set 2)
CS/IT Gate 2015 (Set 1)
CS/IT Gate 2015 (Set 2)
CS/IT Gate 2015 (Set 3)
CS/IT Gate 2014 (Set 1)
CS/IT Gate 2014 (Set 2)
CS/IT Gate 2014 (Set 3)
CS and IT Gate 2026 Set-2 Questions with Answer
Ques 27 GATE 2026 SET-2
Let 𝐺 be a weighted directed acyclic graph with 𝑚 edges and 𝑛 vertices. Given 𝐺 and a source vertex 𝑠 in 𝐺, which one of the following options gives the worst case time complexity of the fastest algorithm to find the lengths of shortest paths from 𝑠 to all vertices that are reachable from 𝑠 in 𝐺?
The correct answer is Option A — Θ(m + n).
For a weighted directed acyclic graph (DAG), the fastest shortest path algorithm exploits the fact that a DAG has no cycles, allowing a topological sort-based approach that is more efficient than both Dijkstra and Bellman-Ford.
Algorithm:
Topological Sort: Compute a topological ordering of all vertices in G using DFS. This takes Θ(m + n) time.
Relax edges in topological order: Initialize dist[s] = 0 and dist[v] = ∞ for all other vertices. Process each vertex u in topological order — for every outgoing edge (u, v) with weight w, update dist[v] = min(dist[v], dist[u] + w). Each edge is relaxed exactly once → Θ(m + n) total.
Total: Θ(m + n).
Why the other options are incorrect:
Option B — Θ(m + n log n): This is the complexity of Dijkstra''s algorithm using a binary heap. Dijkstra requires a priority queue and cannot handle negative weights, making it suboptimal for a DAG. Incorrect.
Option C — Θ(nm): This is Bellman-Ford's complexity, which is needed for general graphs with negative edges but is far too slow for a DAG. Incorrect.
Option D — Θ(n²): This corresponds to Dijkstra using an adjacency matrix, which is even slower. Incorrect.
The key advantage of the DAG algorithm is that it works correctly even with negative edge weights (since there are no negative cycles in a DAG), while achieving the optimal linear time complexity.
Ques 28 GATE 2026 SET-2
Consider an array 𝐴 of integers of size 𝑛. The indices of 𝐴 run from 1 to 𝑛. An
algorithm is to be designed to check whether 𝐴 satisfies the condition given below.
∀𝑖,𝑗∈{1,…,𝑛−1} such that 𝑖>𝑗,(𝐴[𝑖+1]−𝐴[𝑖])> (𝐴[𝑗+1]−𝐴[𝑗])
Which one of the following gives the worst case time complexity of the fastest
algorithm that can be designed for the problem?
The correct answer is Option A - Θ(n).
We just need to check if the differences between consecutive elements are strictly increasing.
Compute di = Ai+1 − Ai, and compare each difference with the next one.
Traverse the array once, and for each i, check if:
(Ai+1 − Ai) < (Ai+2 − Ai+1).
If any condition fails, return false. If all checks pass, return true.
This takes one linear scan of the array.
Time Complexity: Θ(n), since we process each element once.
Ques 29 GATE 2026 SET-2
Consider a table 𝑇, where the elements 𝑇[𝑖][𝑗],0≤𝑖,𝑗≤𝑛, represent the cost of
the optimal solutions of different subproblems of a problem that is being solved
using a dynamic programming algorithm. The recursive formulation to compute the
table entries is as follows:
T[0][𝑘]=𝑇[𝑘][0]=1 for 𝑘=0,1,2,…,𝑛
T[𝑖][𝑗]=2𝑇[𝑖−1][𝑗]+ 3𝑇[𝑖][𝑗−1] for 1≤𝑖,𝑗≤𝑛

The correct answer is Option A — Both algorithms B₁ and B₂ are correct.
To verify correctness, we must confirm that for each algorithm, whenever T[i][j] is computed, its two dependencies — T[i−1][j] (row above, same column) and T[i][j−1] (same row, previous column) — have already been correctly computed.
Algorithm B₁ — Row-by-row, left-to-right: The outer loop iterates over rows i = 1 to n, and the inner loop over columns j = 1 to n. When T[i][j] is about to be computed, T[i−1][j] belongs to row i−1, which was fully computed in an earlier outer iteration. T[i][j−1] belongs to the current row but was computed at the previous j step in the inner loop. Both dependencies are satisfied in the correct order. B₁ is correct.
Algorithm B₂ — Anti-diagonal order: The outer loop iterates over the anti-diagonal sum s = i+j, from 2 to 2n. All cells with i+j = s are computed together in one pass. When T[i][j] (with i+j = s) is being computed: T[i−1][j] has index sum (i−1)+j = s−1, belonging to the previous anti-diagonal. T[i][j−1] has index sum i+(j−1) = s−1, also on the previous anti-diagonal. Since s−1 < s, both dependencies were fully computed before the current diagonal s is processed. B₂ is correct.
The key insight is that the recurrence T[i][j] = 2T[i−1][j] + 3T[i][j−1] requires dependencies that lie either on the previous row (i−1) or the previous column position (j−1). Both row-major order (B₁) and anti-diagonal order (B₂) satisfy this dependency constraint, making both algorithms valid bottom-up DP traversal strategies.
Ques 30 GATE 2026 SET-2
Consider the following 4-variable Boolean function
F(A, B, C, D) = Σm(0,1,2,3,8,9,10,11)
Consider 𝐴 as MSB, 𝐷 as LSB. Which one of the following options represents the
minimal sum of products form for the above function?
Note: + is OR operation, . is AND operation, ′ is NOT operation
The correct answer is Option B — B''''.
The function F(A, B, C, D) = Σm(0,1,2,3,8,9,10,11) with A as MSB and D as LSB can be analysed by converting each minterm to its binary representation. The minterms are: m0=0000, m1=0001, m2=0010, m3=0011, m8=1000, m9=1001, m10=1010, m11=1011.
Pattern recognition: All minterms have B = 0 (the second bit is 0 in all cases). The values of A, C, and D vary freely among these minterms — A is either 0 or 1, C is either 0 or 1, and D is either 0 or 1. The only constant is B = 0.
Verification: B'''' (B = 0) covers exactly minterms where the second bit is 0, which includes all 8 minterms: 0,1,2,3,8,9,10,11 (matches the given set exactly) and also 4,5,6,7,12,13,14,15... wait, that''''s 16 minterms total for B=0.
Actually — let me recount. For 4 variables with B=0, there are 2³ = 8 combinations of (A,C,D). These 8 minterms are exactly 0,1,2,3,8,9,10,11 ✓.
Therefore the minimal sum-of-products form is simply F = B''''.
Ques 31 GATE 2026 SET-2
Consider the canonical 𝐿𝑅(0) parsing of the grammar below using terminals
{𝑎,𝑏,𝑐} and non-terminals {𝐴,𝐵,𝐶,𝑆} with 𝑆 as the start symbol.
S→𝐴𝐶𝐵
A→𝑎𝐴 | 𝜖
C→𝑐𝐶 | 𝜖
B→𝑏𝐵 | 𝑏
Which one of the following options gives the number of shift-reduce conflicts that
will occur in the 𝐿𝑅(0) ACTION table?
The correct answer is Option D — 5 shift-reduce conflicts.
A shift-reduce conflict in an LR(0) state occurs when the state contains both a complete item (dot at the end → reduce) and an item with the dot before a terminal (→ shift). The grammar has ε-productions for A and C, which introduce complete items into states alongside shift items, creating conflicts.
State I0 contains A→• (reduce A→ε) and A→•aA (shift ''''a'''') → Conflict 1.
State I1 = GOTO(I0, A) contains C→• (reduce C→ε) and C→•cC (shift ''''c'''') → Conflict 2.
State I2 = GOTO(I0, a) contains A→• (reduce A→ε) and A→•aA (shift ''''a'''') → Conflict 3.
State I5 = GOTO(I1, c) contains C→• (reduce C→ε) and C→•cC (shift ''''c'''') → Conflict 4.
State I8 = GOTO(I4, b) contains B→b• (reduce) and B→b•B (shift ''''b'''') → Conflict 5.
No other states produce shift-reduce conflicts. The B production B→bB|b causes a conflict because both B→b• and B→b•B appear in the same state. The ε-productions of A and C each cause conflicts in two states — one at the initial state and one in the recursive state.
Ques 32 GATE 2026 SET-2
In the context of schema normalization in relational DBMS, consider a set F of
functional dependencies. The set of all functional dependencies implied by F is
called the closure of F. To compute the closure of F, Armstrong’s Axioms can be
applied. Consider 𝑋,𝑌, and 𝑍 as sets of attributes over a relational schema. The three
rules of Armstrong’s Axioms are described as follows.
Reflexivity: If 𝑌⊆𝑋 , then 𝑋→𝑌
Augmentation: If 𝑋→𝑌, then 𝑋𝑍→𝑌𝑍 for any Z
Transitivity: If 𝑋→𝑌 and 𝑌→𝑍, then 𝑋→𝑍
The additional rule of Union is defined as follows.
Union: If 𝑋→𝑌 and 𝑋→𝑍, then 𝑋→𝑌𝑍
It can be proved that the additional rule of Union is also implied by the three rules
of Armstrong’s Axioms. Listed below are four combinations of these three rules.
Which one of these combinations is both necessary and sufficient for the proof ?
The Union rule states: if X→Y and X→Z, then X→YZ. To prove this using Armstrong''s Axioms, we need to find the minimal combination of rules that makes this proof possible.
The proof works as follows. Start with X→Z. Apply Augmentation by adding X to both sides — since augmenting X→Z with X gives XX→XZ, and XX simplifies to X, we get X→XZ. Next, take X→Y and apply Augmentation by adding Z to both sides, giving XZ→YZ. Now we have X→XZ and XZ→YZ. Applying Transitivity to these two gives X→YZ, which is exactly the Union rule. The proof is complete using only Augmentation and Transitivity.
Reflexivity is never used in any step of this proof, so option A is incorrect — it includes an unnecessary rule and fails the "necessary" condition. Option B has Reflexivity and Augmentation but without Transitivity there is no way to chain X→XZ and XZ→YZ into X→YZ. Option C has only Transitivity but without Augmentation neither X→XZ nor XZ→YZ can be derived from the given dependencies.
Correct answer: D — Augmentation and Transitivity ✓
Ques 33 GATE 2026 SET-2
Consider the transmission of data bits 110001011 over a link that uses Cyclic Redundancy Check (CRC) code for error detection. If the generator bit pattern is given to be 1001, which one of the following options shows the remainder bit pattern appended to the data bits before transmission?
The correct answer is Option D — 100.
CRC setup: Generator = 1001 (degree 3), so append 3 zeros to the data. Message with zeros = 110001011000 (12 bits). Divide this by 1001 using modulo-2 (XOR) division.
XOR division step by step (each step: if MSB=1 XOR with 1001, else XOR with 0000, bring down next bit):
1100 XOR 1001 = 0101, bring down 0 → 1010
1010 XOR 1001 = 0011, bring down 1 → 0111
0111 XOR 0000 = 0111, bring down 0 → 1110
1110 XOR 1001 = 0111, bring down 1 → 1111
1111 XOR 1001 = 0110, bring down 1 → 1101
1101 XOR 1001 = 0100, bring down 0 → 1000
1000 XOR 1001 = 0001, bring down 0 → 0010
0010 XOR 0000 = 0010, bring down 0 → 0100
Final remainder = 100. This 3-bit remainder is appended to the original data before transmission.
Ques 34 GATE 2026 SET-2
Consider a processor that has 16 general purpose registers and it uses 2-byte instruction format for all its instructions. Variable-sized opcodes are permitted. There are three different types of instructions; M-type, R-type, and C-type. Each M-type instruction has 2 register operands and a 6-bit immediate operand. Each R type instruction has 3 register operands. Each C-type instruction has a register operand and a 6-bit offset value. If there are 2 unique M-type opcodes and 7 unique R-type opcodes, which one of the following options gives the maximum number of unique opcodes possible for C-type instructions?
The processor uses a 16-bit (2-byte) instruction format with 16 registers, so each register field needs 4 bits. Variable-sized opcodes mean unused opcode space at one level can be extended to the next level by adding more bits.
First, figure out how many bits each instruction type leaves for the opcode:
M-type has 2 register fields (4+4 = 8 bits) and a 6-bit immediate, totalling 14 bits of operands. This leaves 16 − 14 = 2 bits for the opcode. So M-type opcodes are 2 bits wide, giving 22 = 4 possible M-type opcodes. Only 2 are used, leaving 2 unused 2-bit prefixes.
R-type has 3 register fields (4+4+4 = 12 bits) of operands, leaving 16 − 12 = 4 bits for the opcode. R-type opcodes are 4 bits wide. To avoid conflicting with M-type''s 2-bit opcodes (00 and 01), R-type must use the 2 remaining 2-bit prefixes (say 10 and 11) and extend each to 4 bits. This gives 2 × 22 = 8 possible R-type opcodes. We need 7, so both unused M-type prefixes are consumed for R-type, and only 1 out of 8 R-type slots remains unused.
C-type has 1 register field (4 bits) and a 6-bit offset, totalling 10 bits of operands, leaving 16 − 10 = 6 bits for the opcode. C-type opcodes are 6 bits wide. The only space left is the 1 unused 4-bit R-type prefix, which can be extended by 2 more bits to form 6-bit C-type opcodes. This gives 1 × 22 = 4 possible C-type opcodes.
Correct answer: B — 4 ✓
Ques 35 GATE 2026 SET-2
Consider the control flow graph given below.
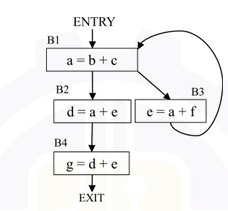
Which one of the following options is the set of live variables at the exit point of each basic block?
The correct answer is Option A — B1: {a, b, c, e, f}, B2: {d, e}, B3: {b, c, e, f}, B4: φ.
Live variable analysis is computed backwards from EXIT. A variable is live at a point if it will be used before being redefined on some path from that point. For each block: USE = variables read before being written; DEF = variables written. LiveOut[B] = union of LiveIn of all successors; LiveIn[B] = USE[B] ∪ (LiveOut[B] − DEF[B]).
B4 (g = d + e): No successors → LiveOut[B4] = φ. LiveIn[B4] = {d, e}.
B2 (d = a + e): Successor is B4 → LiveOut[B2] = LiveIn[B4] = {d, e}. LiveIn[B2] = {a, e} ∪ ({d, e} − {d}) = {a, e}.
B3 (e = a + f): Successor is B1 (back edge) → LiveOut[B3] = LiveIn[B1]. After iterating to fixed point: LiveIn[B1] = {b, c, e, f} → LiveOut[B3] = {b, c, e, f}. LiveIn[B3] = {a, f} ∪ ({b, c, e, f} − {e}) = {a, b, c, f}.
B1 (a = b + c): Successors are B2 and B3 → LiveOut[B1] = LiveIn[B2] ∪ LiveIn[B3] = {a, e} ∪ {a, b, c, f} = {a, b, c, e, f}. LiveIn[B1] = {b, c} ∪ ({a, b, c, e, f} − {a}) = {b, c, e, f}.
The iteration converges with LiveOut values: B1 = {a, b, c, e, f}, B2 = {d, e}, B3 = {b, c, e, f}, B4 = φ.
Ques 36 GATE 2026 SET-2
An index in a DBMS is said to be dense if an index entry appears for every
search-key value in the indexed file. Otherwise it is called a sparse index. Consider
the following two statements.
S1: A hash index must be a dense index
S2: A B+ tree index can be a sparse index
Which one of the following options is correct?
The correct answer is Option A - Both S1 and S2 are true.
An index is called dense if it contains an entry for every search-key value in the file. If some search-key values do not have corresponding entries, the index is called sparse.
S1: A hash index must be a dense index
In hash indexing, a hash function is used to map each search-key value directly to a bucket. For efficient equality search, the system needs to locate records using the exact key, so entries are maintained for every search-key value. Collisions are handled within buckets, but the index still points to all values. Hence, hash indexes are dense. So, S1 is true.
S2: A B+ tree index can be a sparse index
B+ tree indexes allow flexibility in how entries are stored. At the leaf level, it is possible to store entries for every record (making it dense). However, in cases like primary or clustered indexing, the leaf nodes may store entries only for the first record of each block, along with block pointers. This makes the index sparse. Hence, a B+ tree can be implemented as a sparse index. So, S2 is true.
Therefore, both S1 and S2 are true.
Ques 37 GATE 2026 SET-2
Consider the following two finite automata D₁ and D₂.
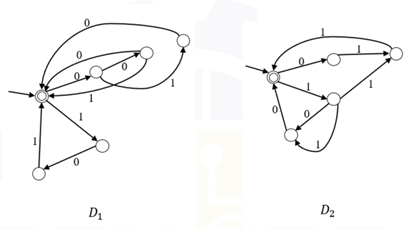
The correct answers are Option C and Option D.
The DFAs D1 and D2 are defined over the alphabet Σ = {0,1}, and each accepts strings formed by concatenating specific 3-bit blocks.
L(D1) consists of strings formed using blocks like 000, 001, 010, 101.
L(D2) consists of strings formed using the remaining blocks like 011, 100, 110, 111.
Option A is false:
L(D1) ≠ L(D2). For example, “000” is accepted by D1 but not by D2, while “011” is accepted by D2 but not by D1.
Option B is false:
Neither language is a subset of the other, since each accepts strings that the other does not.
Option C is true:
The 3-bit blocks used in D1 and D2 are disjoint. So, no non-empty string can belong to both languages. The only common string is the empty string ε.
Hence, L(D1) ∩ L(D2) = {ε}.
Option D is true:
The union L(D1) ∪ L(D2) contains all possible 3-bit strings. Repeating these blocks any number of times (including zero) generates all strings whose length is a multiple of 3.
Hence, (L(D1) ∪ L(D2)* ) generates all strings over {0,1} with length divisible by 3.
Ques 38 GATE 2026 SET-2
Let Σ = {a, b, c, d} and let L = {aⁱ bʲ cᵏ dˡ | i, j, k, ℓ ≥ 0}. Which of the following constraints ensure(s) that the language L is context-free?
The correct answers are Options A, C, and D
Option A — i + k = j + ℓ: This is a linear balance constraint. A PDA can handle it by pushing for every ''''a'''' read, popping for every ''''b'''', pushing for every ''''c'''', and popping for every ''''d''''. The stack is empty at the end iff i − j + k − ℓ = 0, i.e., i + k = j + ℓ. CFL ✓ Correct.
Option B — i = k and j = ℓ: This gives the language {aⁱ bʲ cⁱ dʲ}, which requires two independent cross-serial counts to be matched simultaneously. A single-stack PDA cannot compare both i with k and j with ℓ independently when they interleave. This is a context-sensitive language. Not CFL ✗ Incorrect.
Option C — i = ℓ and j = k: This gives the language {aⁱ bʲ cʲ dⁱ}, which has a perfectly nested structure. A PDA pushes i a''''s, then pushes j b''''s, then pops j for c''''s (matching j = k), then pops i for d''''s (matching i = ℓ). A simple grammar S → aSd | T, T → bTc | ε generates exactly this language. CFL ✓ Correct.
Option D — i + j = k + ℓ: Another linear balance constraint. A PDA pushes for every ''''a'''' and ''''b'''', and pops for every ''''c'''' and ''''d''''. The stack is empty iff i + j = k + ℓ. CFL ✓ Correct.
Ques 39 GATE 2026 SET-2
Consider a binary search tree (BST) with 𝑛 leaf nodes (𝑛>0). Given any node 𝑉,
the key present in the node is denoted as 𝑉𝑎𝑙(𝑉). All the keys present in the given
BST are distinct. The keys belong to the set of real numbers.
For a node 𝑉, let 𝑆𝑢𝑐(𝑉) denote the node that is its inorder successor. If a node 𝑉
does not have an inorder successor, then 𝑆𝑢𝑐(𝑉) is 𝑁𝑈𝐿𝐿. As there are no
duplicates, if 𝑆𝑢𝑐(𝑉) is not 𝑁𝑈𝐿𝐿, then 𝑉𝑎𝑙(𝑉) <𝑉𝑎𝑙(𝑆𝑢𝑐(𝑉)).
Corresponding to every leaf node 𝐿𝑖 that has a non-NULL 𝑆𝑢𝑐(𝐿𝑖), a new key 𝑘𝑖
with the following property is to be inserted into the BST.
V𝑎𝑙(𝐿𝑖)< 𝑘𝑖< 𝑉𝑎𝑙(𝑆𝑢𝑐(𝐿𝑖))
Let 𝐾 represent the list of all such new keys to be inserted into the BST.
Which of the following statements is/are true?
Each new key ki satisfies Val(Li) < ki < Val(Suc(Li)), inserted for every leaf that has a non-NULL inorder successor.
Option A — True
In a BST the inorder sequence is strictly sorted and all keys are distinct. The interval (Val(Li), Val(Suc(Li))) for each leaf is completely disjoint from every other leaf's interval — no two leaves share the same consecutive inorder pair. Since all intervals are non-overlapping, it is impossible for two different ki values chosen from different intervals to be equal. K cannot have duplicates. A is true.
Option B — True
Any BST with more than one node always has at least one leaf that is not the rightmost node, meaning at least one leaf has a non-NULL inorder successor. So K always has at least one element. B is true.
Option C — True
Since ki > Val(Li) and Li is a leaf with no right child, every new key inserts as a direct right child of Li, exactly one level below an existing leaf. Height increases by at most 1. C is true.
Option D — False
The rightmost leaf has no inorder successor and contributes nothing to K. So new nodes inserted are strictly less than n, and total nodes cannot reach 2n. Doubling is impossible. D is false.
Correct answer: A, B, C

Total Unique Visitors