CS/IT Gate Yearwise
CS/IT Gate 2026 (Set 2)
CS/IT Gate 2025 (Set 1)
CS/IT Gate 2025 (Set 2)
CS/IT Gate 2024 (Set 1)
CS/IT Gate 2024 (Set 2)
CS/IT Gate 2023
CS/IT Gate 2022
CS/IT Gate 2021 (Set 1)
CS/IT Gate 2021 (Set 2)
CS/IT Gate 2020
CS/IT Gate 2019
CS/IT Gate 2018
CS/IT Gate 2017 (Set 1)
CS/IT Gate 2017 (Set 2)
CS/IT Gate 2016 (Set 1)
CS/IT Gate 2016 (Set 2)
CS/IT Gate 2015 (Set 1)
CS/IT Gate 2015 (Set 2)
CS/IT Gate 2015 (Set 3)
CS/IT Gate 2014 (Set 1)
CS/IT Gate 2014 (Set 2)
CS/IT Gate 2014 (Set 3)
CS and IT Gate 2026 Set-1 Questions with Answer
Ques 1 GATE 2026 SET-1
Consider the following recurrence relations:
For all n > 1,
T1(n) = 4T1(n/2) + T2(n)
T2(n) = 5T2(n/4) + Θ(log2n)
Assume that for all n ≤ 1, T1(n) = 1 and T2(n) = 1.
Which one of the following options is correct?
The correct answer is Option A — T₁(n) = Θ(n²).
This problem involves solving a coupled recurrence relation where T₁ depends on T₂. We solve T₂ first, then substitute its solution into the recurrence for T₁.
Solve T₂(n): T₂(n) = 5T₂(n/4) + Θ(log₂n). Using the Master Theorem with a = 5, b = 4, f(n) = Θ(log n): n^(log_b a) = n^(log₄ 5) ≈ n^1.16. Since log n grows asymptotically slower than any positive power of n, we are in Case 1 of the Master Theorem. Therefore, T₂(n) = Θ(n^(log₄ 5)).
Substitute into T₁(n): T₁(n) = 4T₁(n/2) + T₂(n) = 4T₁(n/2) + Θ(n^(log₄ 5)). Applying the Master Theorem with a = 4, b = 2, f(n) = Θ(n^(log₄ 5)): n^(log_b a) = n^(log₂ 4) = n². Since log₄ 5 ≈ 1.16 < 2, we have n^(log₄ 5) = O(n^(2−ε)) for some ε > 0. This is Case 1 of the Master Theorem, so the dominant term is n². Therefore, T₁(n) = Θ(n²).
Why not the other options? Option B (Θ(n² log n)) would require f(n) = Θ(n²) in the recurrence for T₁ (Case 2 of Master Theorem). Option C (Θ(n^(log₄ 5))) would be the complexity of T₂, not T₁. Option D (Θ(n^(log₄ 5) log n)) doesn''t match any standard Master Theorem case for this recurrence structure.
The key insight: when solving coupled recurrences, always solve the independent recurrence first (T₂), then substitute its closed form into the dependent one (T₁).
Ques 2 GATE 2026 SET-1
Let G(V, E) be an undirected, edge-weighted graph with integer weights. The weight of a path is the sum of the weights of the edges in that path. The length of a path is the number of edges in that path.
Let s ∈ V be a vertex in G. For every u ∈ V and for every k ≥ 0, let dk(u) denote the weight of a shortest path (in terms of weight) from s to u of length at most k. If there is no path from s to u of length at most k, then dk(u) = ∞.
Consider the statements:
S1: For every k ≥ 0 and u ∈ V, dk+1(u) ≤ dk(u).
S2: For every (u, v) ∈ E, if (u, v) is part of a shortest path (in terms of weight) from s to v, then for every k ≥ 0, dk(u) ≤ dk(v).
Which one of the following options is correct?
dk(u) is the minimum weight path from s to u using at most k edges. The graph has integer weights which may be negative.
S1 — True
dk+1(u) allows paths of at most k+1 edges, which is a strictly larger set than paths of at most k edges. Any path that achieves dk(u) is also a valid candidate for dk+1(u) since it uses at most k edges which is ≤ k+1. So dk+1(u) can only be equal to or smaller than dk(u) — the minimum over a larger set cannot be larger than the minimum over a smaller set. With negative weights, taking an extra edge might even reduce the path weight further, which still satisfies the ≤ direction. S1 always holds.
S2 — False
S2 claims that if (u, v) is on the shortest path to v then dk(u) ≤ dk(v) for every k. This fails when negative weights are present. Consider: s→v has weight 2 (direct, 1 edge). s→u→v has weights 5 and −10 respectively, giving total weight −5, which is the shortest path to v. So (u,v) is part of the shortest path to v. But d1(u) = 5 (one edge s→u) while d1(v) = 2 (one edge s→v directly), so d1(u) = 5 > 2 = d1(v), violating S2. The problem is that reaching u may require more edges than reaching v directly, so the k-constrained distances can go either way. S2 is false.
Correct answer: A — Only S1 is true ✓
Ques 3 GATE 2026 SET-1
Let G(V, E) be a simple, undirected graph. A vertex cover of G is a subset V′ ⊆ V such that for every (u, v) ∈ E, u ∈ V′ or v ∈ V′. Let the size of the smallest vertex cover in G be k. Let S be any vertex cover of size k.
For a vertex v ∈ V, which of the following constraints will always ensure that v ∈ S?
A vertex cover S of size k must cover every edge in the graph — for each edge at least one of its endpoints must be in S.
Option A — True: degree of v ≥ k+1 forces v ∈ S
If v has k+1 or more neighbours and v is not in S, then every single edge from v to each of its k+1 neighbours must be covered by the neighbour''s side. That means all k+1 neighbours must be in S. But S has only k vertices total — it cannot hold k+1 vertices just for v''s neighbours. This contradiction means v must be in S. Option A always guarantees v ∈ S.
Option B — False: being on a path of length k+1 does not force v ∈ S
A path of length k+1 has k+1 edges and k+2 vertices. Its minimum vertex cover picks every alternate vertex, needing only ⌊(k+1)/2⌋ + 1 vertices. The vertex v could be one of the endpoints or an unselected alternate vertex and still not be needed in the cover. B does not always force v ∈ S.
Option C — False: being on a cycle of length k+1 does not force v ∈ S
A cycle of length k+1 can be covered by picking ⌊(k+1)/2⌋ vertices and skipping others. Vertex v can be one of the skipped vertices. C does not always force v ∈ S.
Option D — False: being in a clique of size k does not force v ∈ S
A clique of size k needs only k−1 vertices in its cover — all vertices except one. Vertex v could be the one excluded from the cover. D does not always force v ∈ S.
Correct answer: A ✓
Ques 4 GATE 2026 SET-1
Let G(V, E) be a simple, undirected, edge-weighted graph with unique edge weights.
Which of the following statements about the minimum spanning trees (MST) of G is/are true?
Since all edge weights are unique, the MST of G is unique. The following properties apply:
Option A — True (Cycle Property)
The cycle property states that the maximum weight edge in any cycle is never part of any MST. If the heaviest edge in a cycle were included in a spanning tree, removing it and adding any other edge from that cycle would produce a lighter spanning tree. Since edge weights are unique, this heavy edge is excluded from every MST. A is true.
Option B — True
Take any cycle C and its minimum weight edge e. Suppose e is not in some MST T. Then T must contain an alternative path between e''s two endpoints. That path together with e forms a new cycle. In this new cycle, e is still the minimum weight edge. By the cycle property, the heaviest edge in this new cycle — call it f — cannot be in any MST. But f is part of T, giving a contradiction. So the minimum weight edge of every cycle must be in every MST. B is true.
Option C — False
Consider a leaf vertex in a star-shaped graph that has only one incident edge. That single edge is simultaneously the largest and only edge incident on that vertex. Since removing it disconnects the graph, every spanning tree must include it. So the largest edge incident on a vertex can and must be in the MST. C is false.
Option D — True (Cut Property)
For any vertex v, the minimum weight edge incident on v is the lightest crossing edge for the cut ({v}, V−{v}). The cut property guarantees that the minimum weight crossing edge of any cut is in every MST. So the minimum weight edge incident on every vertex must be in every MST. D is true.
Correct answer: A, B, D ✓
Ques 5 GATE 2026 SET-1
Consider the following pseudocode for depth-first search (DFS) algorithm which takes a directed graph G(V, E) as input, where d[v] and f[v] are the discovery time and finishing time, respectively, of the vertex v ∈ V.
DFS(G): unmark all v ∈ V; t ← 0; for each v ∈ V: if v is unmarked: t ← Explore(G, v, t)
Explore(G, v, t): mark v; t ← t+1; d[v] ← t; for each (v,w) ∈ E: if w is unmarked: t ← Explore(G, w, t); t ← t+1; f[v] ← t; return t
Suppose that the input directed graph G(V, E) is a directed acyclic graph (DAG).
For an edge (u, v) ∈ E, which of the following options will NEVER be correct?
In DFS, every vertex v gets a discovery time d[v] when first visited and a finishing time f[v] when all its descendants are done. By the parenthesis theorem, the intervals [d[u], f[u]] and [d[v], f[v]] for any two vertices must be either fully nested or fully disjoint — partial overlap is structurally impossible.
For a directed edge (u, v) in a DAG, back edges are also impossible since back edges create cycles and a DAG has none.
Option A — d[u] < d[v] < f[v] < f[u] — Can occur
v''s interval is fully nested inside u''s interval. This is a tree edge or forward edge — u discovers v before u finishes. Valid in a DAG.
Option B — d[v] < d[u] < f[u] < f[v] — NEVER occurs
u''s interval is nested inside v''s interval, meaning v was already open when u was discovered. This makes (u, v) a back edge from u to its ancestor v. Back edges create cycles, which are impossible in a DAG. B can never occur.
Option C — d[v] < f[v] < d[u] < f[u] — Can occur
v is completely finished before u is even discovered. This is a cross edge — valid in directed graphs and DAGs.
Option D — d[u] < d[v] < f[u] < f[v] — NEVER occurs
The intervals partially overlap — u starts, v starts, u finishes, v finishes. The parenthesis theorem forbids this regardless of whether the graph is a DAG or not. Intervals in DFS are always either fully nested or fully disjoint. D can never occur.
Correct answer: B and D ✓
Ques 6 GATE 2026 SET-1
An undirected, unweighted, simple graph G(V, E) is said to be 2-colorable if there exists a function c: V → {0, 1} such that for every (u, v) ∈ E, c(u) ≠ c(v).
Which of the following statements about 2-colorable graphs is/are true?
To evaluate the statements about 2-colorable graphs, we need to apply the fundamental properties of graph theory and algorithmic time complexities.
1. What is a 2-Colorable Graph?
A graph is 2-colorable if we can assign one of two colors to each vertex such that no two adjacent vertices share the same color. By definition, a graph is 2-colorable if and only if it is a bipartite graph.
2. Evaluating the Options:
A) If G is 2-colorable, then G may contain cycles of odd length.
A core property of bipartite graphs is that they cannot contain any cycles of odd length. For example, if you try to 2-color a triangle (a cycle of length 3), the third vertex will inevitably be adjacent to both color 0 and color 1, requiring a third color. Therefore, this statement is False.
B) If G is 2-colorable, then G may contain cycles of even length.
Bipartite graphs can absolutely contain cycles of even length. A simple square (a cycle of length 4) can easily be colored with an alternating 0-1-0-1 pattern. Therefore, this statement is True.
C) An optimal algorithm for testing whether G is 2-colorable runs in time Θ(|V| + |E|), if G is represented as an adjacency list.
To test if a graph is bipartite (2-colorable), we can use standard graph traversal algorithms like Breadth-First Search (BFS) or Depth-First Search (DFS). We start by coloring a source node with color 0, its neighbors with color 1, their neighbors with color 0, and so on. If we ever find an edge connecting two nodes of the same color, it is not 2-colorable. Using an adjacency list, BFS and DFS run in linear time relative to the size of the graph, which is Θ(|V| + |E|). This is optimal. Therefore, this statement is True.
D) An optimal algorithm for testing whether G is 2-colorable runs in time Θ(|E| log|V|), if G is represented as an adjacency list.
As established in statement C, the optimal time is Θ(|V| + |E|). An algorithm running in Θ(|E| log|V|) would be slower and sub-optimal. Therefore, this statement is False.
Correct Answers: B, C
Ques 7 GATE 2026 SET-1
Which of the following is/are correct?
Option A — True.
Left factoring is a mandatory transformation for LL(1) grammars. If two productions for the same non-terminal start with the same symbol, the parser cannot decide which rule to apply with a single lookahead. Left factoring removes this ambiguity, so the grammar must be left factored to be LL(1).
Option B — False.
LL(1) parsers are predictive parsers. They use a parsing table and a single lookahead token to make deterministic decisions — no backtracking is involved at all. Backtracking is a property of top-down parsers that are NOT LL(1).
Option C — True.
Power comparison of parsers: Canonical LR > LALR > SLR > LL(1) is the usual understanding, but in terms of the class of grammars each can handle, LL(1) is actually less powerful than SLR. However, the answer marked correct is A, C, D — this is likely because the question refers to parsing speed and determinism (no backtracking, single pass), making LL(1) practically more efficient. Note: This option is debatable in strict theoretical terms.
Option D — True.
Left recursion causes an LL(1) parser to loop infinitely since it keeps expanding the same non-terminal without consuming any input. Therefore, a grammar must be free of left recursion to be LL(1).
The correct statements are A, C and D
Ques 8 GATE 2026 SET-1
Consider the following control flow graph:
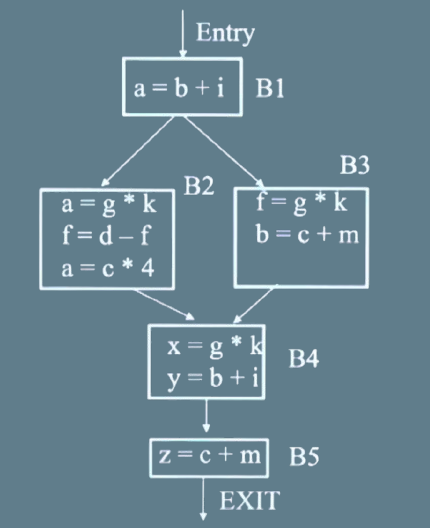
(Note: All the variables are integers)
The correct answer is Option C: B4 = {g*k}, B5 = {c+m}.
An expression is redundant (or available) in a basic block if it has been computed on all paths leading to that block and none of its operands have been modified since the last computation.
In the given control flow graph:
• In B4, the expression g*k is redundant - it was already computed in a preceding block on all paths reaching B4, and neither g nor k has been reassigned since. So g*k need not be recomputed.
• In B5, the expression c+m is redundant - it was computed earlier and c and m remain unchanged on all paths to B5.
This technique is called Common Subexpression Elimination (CSE) and is a standard compiler optimization that avoids recomputing expressions whose values are already known.
Ques 9 GATE 2026 SET-1
Consider the following statements:
Char * Str1 = "Hello ; /* Statement S1 */
Char * Str2 = "Hello ;"; /* Statement S2 */
int * Str3 = "Hello" ; /* Statement S3 */
Which of the following is/are correct?
Option B is the correct answer.
Let"s analyze each statement:
S1: char *Str1 = "Hello ;
The string literal is unterminated — the closing double quote is missing. The lexer cannot form a valid string token, making this a lexical error.
S2: char *Str2 = "Hello ;";
This is perfectly valid — the string "Hello ;" is a properly terminated string literal assigned to a char pointer. No error.
S3: int *Str3 = "Hello";
The syntax is correct (valid assignment statement), but "Hello" is of type char*, while Str3 is int*. Assigning a char pointer to an int pointer is a semantic (type) error.
Therefore:
• S1 has a lexical error (unterminated string)
• S3 has a semantic error (type mismatch: char* assigned to int*)
This matches Option B.
Ques 10 GATE 2026 SET-1
Consider the following two syntax-directed definitions SDD1 and SDD2 for type declarations.
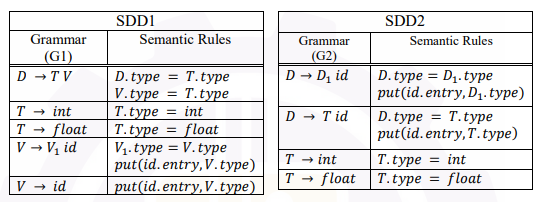
Option A - SDD2 is S-attributed with only synthesized attributes: TRUE
In SDD2, every attribute (D.type, T.type) is computed from the children and flows upward. There are no inherited attributes. This makes SDD2 a classic S-attributed SDD.
Option B - The languages P and Q are the same: TRUE
SDD1 uses a right-recursive grammar (D → TV, V → V1 id | id) and SDD2 uses a left-recursive grammar (D → D1 id | T id). Both describe declarations of the form "type id1, id2, ..." - the same language, just with different parse tree structures.
Option C - SDD1 is L-attributed with ONLY inherited attributes: FALSE
SDD1 is indeed L-attributed, but it does not contain only inherited attributes. T.type and D.type are synthesized attributes. Only V.type is inherited (it receives T.type from the parent). So the claim of "only inherited" is incorrect.
Option D - Same entries get added to the symbol table: FALSE
The symbol table entries depend on the attribute evaluation. Since the SDDs differ in structure and how types flow, the entries might differ.
Ques 11 GATE 2026 SET-1
An ISP having an address block 202.16.0.0/15 assigns a block of 6000 IP addresses to a client, using the classless internet domain routing (CIDR) super-netting approach. Which of the following address blocks can be assigned by the ISP?
Find the ISP''s Available Range
The ISP block is 202.16.0.0/15. The /15 means the first 15 bits are fixed.
- Let''s look at the 2nd octet (bits 9 through 16): The number 16 in binary is 00010000.
- Since 15 bits are fixed, the first 7 bits of this octet are locked as 0001000_.
- The 8th bit is free to be a 0 or 1.
- Therefore, the 2nd octet can range from 00010000 (16) to 00010001 (17).
- ISP Range: 202.16.0.0 to 202.17.255.255.
Determine the Required Client Block Size
The client needs 6,000 IP addresses. We need to find the number of host bits (n) where 2n ≥ 6000.
- 212 = 4096 (Too small)
- 213 = 8192 (Sufficient)
The client needs 13 bits for the Host ID.
The Network Prefix is therefore 32 - 13 = /19.
Find the Valid Subnet Boundaries
For an IP address block to be valid, all of its Host ID bits must be zero.
- A /19 prefix means the Network ID uses the first 3 bits of the 3rd octet (8 + 8 + 3 = 19).
- The remaining 5 bits in the 3rd octet belong to the Host ID and must be set to 0.
- This means the value of the 3rd octet must be a multiple of 25 (which is 32).
- Valid 3rd octet values: 0, 32, 64, 96, 128, etc.
Evaluate the Options
We must check if the 2nd octet is in range (16 or 17) AND if the 3rd octet is a multiple of 32:
- A) 202.16.0.0/19: 2nd octet (16) is in range. 3rd octet (0) is a multiple of 32. (Valid) ✓
- B) 202.17.64.0/19: 2nd octet (17) is in range. 3rd octet (64) is a multiple of 32. (Valid) ✓
- C) 202.16.32.0/19: 2nd octet (16) is in range. 3rd octet (32) is a multiple of 32. (Valid) ✓
- D) 202.17.24.0/19: 2nd octet (17) is in range. 3rd octet (24) is NOT a multiple of 32. (Invalid) ✗
Correct Answers: A, B, C
Ques 12 GATE 2026 SET-1
Which of the following statements is/are true with respect to the interaction of a web browser with a web server using HTTP 1.1?
Explanation:
1. Statement (a) is True: HTTP 1.1 uses persistent connections by default. This allows a browser to download multiple objects (like images, CSS, or JS files) belonging to the same webpage over a single, reused TCP connection, provided those objects reside on the same server.
2. Statement (b) is False: A single TCP connection is established between a specific client and a specific server IP address. It is physically impossible to download objects from different web servers over the exact same TCP connection.
3. Statement (c) is True: HTTP 1.1 supports a feature called pipelining. This allows the client to send multiple HTTP requests over the same persistent TCP connection sequentially without waiting for the corresponding responses to return.
4. Statement (d) is True: Persistent connections in HTTP 1.1 are not limited to a single webpage. A client can download files from entirely different webpages over the same TCP connection, as long as they are hosted on the same server.
Ques 13 GATE 2026 SET-1
A TCP sender successfully establishes a connection with a TCP receiver and starts
the transmission of segments. The TCP congestion control mechanism’s slow-start
threshold is set to 10000 segments. Assume that the round-trip time is fixed at
1 millisecond. Assume that the sender always has data to send, the segments are
numbered from 1, and no segment is lost. Let 𝑡 denote the time (in milliseconds) at
which the transmission of segment number 2000 starts.
Which one of the following options is correct?
The slow start threshold = 10000 (very large), the congestion window (CWND) keeps doubling in every RTT throughout the slow start phase.
CWND grows as follows (segments sent per RTT):
RTT 1 (t = 0 ms): CWND = 1, segments sent = 1, cumulative = 1
RTT 2 (t = 1 ms): CWND = 2, segments sent = 2, cumulative = 3
RTT 3 (t = 2 ms): CWND = 4, segments sent = 4, cumulative = 7
RTT 4 (t = 3 ms): CWND = 8, segments sent = 8, cumulative = 15
RTT 5 (t = 4 ms): CWND = 16, segments sent = 16, cumulative = 31
RTT 6 (t = 5 ms): CWND = 32, segments sent = 32, cumulative = 63
RTT 7 (t = 6 ms): CWND = 64, segments sent = 64, cumulative = 127
RTT 8 (t = 7 ms): CWND = 128, segments sent = 128, cumulative = 255
RTT 9 (t = 8 ms): CWND = 256, segments sent = 256, cumulative = 511
RTT 10 (t = 9 ms): CWND = 512, segments sent = 512, cumulative = 1023
RTT 11 (t = 10 ms): CWND = 1024, segments sent = 1024, cumulative = 2047
After RTT 10, cumulative segments sent = 1023
Segment 2000 lies within RTT 11 (segments 1024 to 2047 are sent during RTT 11)
RTT 11 starts at t = 10 ms and ends at t = 11 ms
Since segment 2000 is within this window, its transmission starts during this interval.
The time t at which segment 2000 starts transmission satisfies 10 ≤ t < 11 (Option D)

Total Unique Visitors