CS/IT Gate Yearwise
CS/IT Gate 2026 (Set 2)
CS/IT Gate 2025 (Set 1)
CS/IT Gate 2025 (Set 2)
CS/IT Gate 2024 (Set 1)
CS/IT Gate 2024 (Set 2)
CS/IT Gate 2023
CS/IT Gate 2022
CS/IT Gate 2021 (Set 1)
CS/IT Gate 2021 (Set 2)
CS/IT Gate 2020
CS/IT Gate 2019
CS/IT Gate 2018
CS/IT Gate 2017 (Set 1)
CS/IT Gate 2017 (Set 2)
CS/IT Gate 2016 (Set 1)
CS/IT Gate 2016 (Set 2)
CS/IT Gate 2015 (Set 1)
CS/IT Gate 2015 (Set 2)
CS/IT Gate 2015 (Set 3)
CS/IT Gate 2014 (Set 1)
CS/IT Gate 2014 (Set 2)
CS/IT Gate 2014 (Set 3)
CS and IT Gate 2025 Set-2 Questions with Answer
Ques 1 GATE 2025 SET-2
Consider an unordered list of N distinct integers.
What is the minimum number of element comparisons required to find an integer in the list that is NOT the largest in the list?
The correct answer is Option A - 1.
This is a beautifully simple question once you see the trick. We need to find any element that is not the largest - we don''t need to find the maximum or sort anything.
Here''s all you need to do: pick any two elements from the list and compare them. Since all integers are distinct, one will be strictly smaller than the other. That smaller element is guaranteed to not be the largest in the entire list - because the element it was just compared to is already larger than it.
So with just 1 comparison, we''ve identified an element that is not the largest.
Options B (N-1), C (N), and D (2N-1) would all be answers if we were trying to find the maximum element. But since we only need any non-largest element, a single comparison is all it takes.
Ques 2 GATE 2025 SET-2
Which of the following statements regarding Breadth First Search (BFS) and Depth First Search (DFS) on an undirected simple graph G is/are TRUE?
The correct answer is Option D — Both BFS and DFS can be used to find the connected components of G.
Let''s evaluate each option for an undirected simple graph G.
Option A - A DFS tree is a shortest path tree: False. DFS dives deep without regard for edge count, so DFS tree paths are not necessarily shortest. It''s BFS that guarantees shortest paths in unweighted graphs.
Option B - Non-tree edges in DFS are forward/back edges: False as stated. In an undirected graph, all non-tree edges in a DFS are back edges only- there are no forward edges or cross edges. The option mentions "forward/back" which makes it incorrect since forward edges don''t appear in undirected DFS.
Option C - Non-tree BFS edge (u,v): distances within ±1: This is actually true for undirected graphs - if (u,v) is a non-tree edge in a BFS tree, then |d(u) − d(v)| ≤ 1. However, the official GATE key marks only D as correct, possibly because the question intends a stricter interpretation or the phrasing implies something broader.
Option D - Both BFS and DFS find connected components: True. Running BFS or DFS from each unvisited vertex and grouping all visited vertices together gives the connected components. Both algorithms explore all reachable vertices from a source, making them equally capable of connected component detection.
Ques 3 GATE 2025 SET-2
Let G be an edge-weighted undirected graph with positive edge weights. Suppose a positive constant a is added to the weight of every edge. Which ONE of the following statements is TRUE about the minimum spanning trees (MSTs) and shortest paths (SPs) in G before and after the edge weight update?
The correct answer is Option C - Every MST remains an MST, but shortest paths need not remain shortest paths.
MST - stays the same:
MST algorithms like Kruskal's and Prim's work on relative edge weights. Adding a constant a to every edge shifts all weights equally, so the ordering of edges doesn't change. The same edges get picked — MST is preserved.
Shortest Path — can change:
A path with k edges gets its total cost increased by k × a. So paths with fewer hops get a smaller penalty than paths with more hops. This imbalance can flip which path is shortest.
Quick example — A→B = 1, B→C = 1, A→C = 3. Shortest path A to C is via B (cost 2). Add a = 3 to all edges: A→B = 4, B→C = 4, A→C = 6. Now A→B→C costs 8, but direct A→C costs 6. The shortest path changed.
MST survives uniform weight addition. Shortest paths don't always.
Ques 4 GATE 2025 SET-2
A meld operation on two instances of a data structure combines them into one single instance of the same data structure. Consider the following data structures:
P: Unsorted doubly linked list with pointers to the head node and tail node of the list.
Q: Min-heap implemented using an array.
R: Binary Search Tree.
Which ONE of the following options gives the worst-case time complexities for meld operation on instances of size n of these data structures?
This question is all about understanding how different data structures behave when you try to combine - or "meld" - two instances of them into one. The trick is knowing the internal structure of each data structure and what the cheapest possible merge strategy looks like for each.
P — Unsorted Doubly Linked List with head and tail pointers: Θ(1)
This one is the simplest. Since we already have a pointer to the tail of the first list and a pointer to the head of the second list, all we need to do is link them together - tail1.next = head2 and head2.prev = tail1. That's it. No traversal, no comparisons, no sorting needed. The list is unsorted, so we don't have any ordering constraints to maintain. The whole operation completes in a fixed number of pointer updates, making it a clean Θ(1).
Q - Min-Heap implemented as an array: Θ(n)
When you meld two min-heaps of size n each, you first concatenate the two underlying arrays to get an array of size 2n. Now this combined array doesn't satisfy the heap property, so you need to restore it. The standard way to do this is the build-heap algorithm - you start heapifying from the last internal node up to the root. Even though each heapify call is O(log n), the total work across all nodes sums up to O(n) - this is a well-known result from the mathematical analysis of build-heap. So the overall meld operation on two min-heaps is Θ(n).
R — Binary Search Tree: Θ(n)
At first glance, people assume merging two BSTs must be at least O(n log n) because inserting n elements one by one into a BST is O(n log n). But there's a smarter approach. You do an in-order traversal of both BSTs - each traversal takes O(n) and gives you a sorted array. Then you merge the two sorted arrays, which is the classic merge step from merge sort - also O(n). Finally, you build a balanced BST from the merged sorted array, which again takes O(n) using the recursive mid-point construction technique. All three steps together make it Θ(n), not Θ(n log n).
So the correct answer is Option A - P: Θ(1), Q: Θ(n), R: Θ(n).
Ques 5 GATE 2025 SET-2
An array A of length n with distinct elements is said to be bitonic if there is an index 1≤i≤n such that A[1..i] is sorted in the non-decreasing order and A[i+1..n] is sorted in the non-increasing order.
Which ONE of the following represents the best possible asymptotic bound for the worst-case number of comparisons by an algorithm that searches for an element in a bitonic array A?
The correct answer is Option D — Θ(log n).
A bitonic array increases up to a peak element and then decreases. To search for a target element efficiently, the algorithm runs in three steps — all using binary search:
Step 1 — Find the peak: Use binary search to locate the index i where the maximum element sits. This takes O(log n).
Step 2 — Binary search on ascending half: Search for the target in A[1..i] (sorted in non-decreasing order) using standard binary search — O(log n).
Step 3 — Binary search on descending half: If not found, search in A[i+1..n] (sorted in non-increasing order) using a modified binary search — O(log n).
The three steps together still give Θ(log n) in the worst case since constants are absorbed in asymptotic notation.
Option A — Θ(n): This would be a linear scan — correct but not the best possible. Incorrect.
Option B — Θ(1): Constant time search in an unsorted/partially sorted array is impossible. Incorrect.
Option C — Θ(log2n): Asymptotically, log2n and log n are identical (differ only by a constant factor). The question distinguishes C and D to test whether the student knows that specifying base 2 is redundant in asymptotic notation — D with the cleaner Θ(log n) is the intended correct form.
Ques 6 GATE 2025 SET-2
Consider the following algorithm someAlgo that takes an undirected graph G as input.

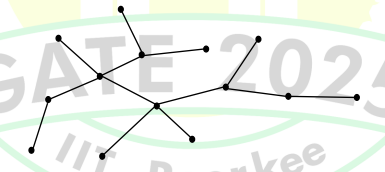
This algorithm computes the diameter of the tree - the longest shortest path between any two vertices.
BFS from any vertex finds the farthest vertex u. BFS from u then finds the farthest vertex z. The distance between u and z is the diameter.
Finding the diameter of tree T:
The tree T in the figure is an unweighted tree. All edges have weight 1.
Starting BFS from any arbitrary vertex v, we find the farthest vertex u.
Then BFS from u finds the farthest vertex z.
The longest path (diameter) in tree T = 6 edges
∴ The output of someAlgo(T) = 6
Ques 7 GATE 2025 SET-2
Consider the following statements about the use of backpatching in a compiler for intermediate code generation:
(I) Backpatching can be used to generate code for Boolean expression in one pass.
(II) Backpatching can be used to generate code for flow-of-control statements in one pass.
Which ONE of the following options is CORRECT?
The correct answer is Option C - Both (I) and (II) are correct.
Backpatching is a classic technique in compiler design used for intermediate code generation to handle forward jumps in a single pass. When a jump instruction is emitted and its target address isn''t known yet, the instruction is left incomplete and added to a list. Once the target becomes known, all instructions in that list are "backpatched" with the correct address.
Statement (I) - Boolean expressions in one pass: True. Boolean expressions like conditions in if-else involve conditional jumps. Backpatching uses truelist and falselist to track incomplete jumps and fills them in when targets are resolved - all in one pass.
Statement (II) - Flow-of-control statements in one pass: True. Statements like if, while, and for all involve forward jumps to addresses not yet known at the time of code generation. Backpatching handles these using nextlist and other lists, enabling one-pass generation of correct jump instructions.
Both statements are correct - backpatching is precisely the mechanism designed to solve both these problems in a single pass.
Ques 8 GATE 2025 SET-2
Given the following syntax directed translation rules:
Rule 1: R→AB {B.i = R.i1; A.i=B.i; R.i=A.i+1;}
Rule 2: P→CD {P.i = C.i+D.i; D.i=C.i+2;}
Rule 3: Q→EF {Q.i = E.i+F.i;}
Which ONE is the CORRECT option among the following?
The correct answer is Option C.
To classify each rule, recall the two definitions:
S-attributed: Only synthesized attributes are used. Every attribute on the LHS is computed solely from RHS attributes - no inherited attributes involved.
L-attributed: Inherited attributes of a RHS symbol can only depend on attributes of symbols to its left in the production, or on inherited attributes of the LHS. Synthesized attributes of the LHS can use any RHS attribute.
Rule 1 - R → AB { B.i = R.i1; A.i = B.i; R.i = A.i + 1; }
A.i is an inherited attribute that depends on B.i - but B is to the right of A in the production. This violates the L-attributed rule. Also, R.i (synthesized) depends on A.i which is inherited - violating S-attributed. So Rule 1 is neither S-attributed nor L-attributed.
Rule 2 - P → CD { P.i = C.i + D.i; D.i = C.i + 2; }
D.i is an inherited attribute that depends on C.i - C is to the left of D, so L-attributed is satisfied. However, P.i (synthesized) depends on D.i which is an inherited attribute - violating pure S-attributed. So Rule 2 is not S-attributed but is L-attributed.
Rule 3 - Q → EF { Q.i = E.i + F.i; }
Q.i is synthesized using only E.i and F.i - both synthesized RHS attributes. No inherited attributes used anywhere. This is purely S-attributed, and since every S-attributed SDT is also L-attributed, Rule 3 is both S-attributed and L-attributed.
This matches Option C exactly.
Ques 9 GATE 2025 SET-2
Given a Context-Free Grammar G as follows:
S→Aa|bAc|dc|bda
A→d
Which ONE of the following statements
The correct answer is Option A - G is neither LALR(1) nor SLR(1).
The grammar is:
S → Aa | bAc | dc | bda
A → d
This is a classic example used to demonstrate the difference between SLR(1)/LALR(1) and CLR(1) parsers. Let''s understand why.
Why G is not SLR(1) or LALR(1):
A → d appears in two different production contexts - S → Aa (where A is followed by ''a'') and S → bAc (where A is followed by ''c''). So FOLLOW(A) = {a, c}.
In the SLR(1) parsing table, when the parser has ''d'' on top of the stack and sees a lookahead of ''a'' or ''c'', it must decide whether to reduce A → d or shift. Additionally, ''d'' also appears directly in S → dc and S → bda, creating a reduce-reduce conflict - the parser can''t determine with just one lookahead whether ''d'' should be reduced as A → d or kept as part of S → dc or S → bda. This conflict makes G not SLR(1).
LALR(1) merges states with the same LR(0) core, but since the conflict originates from overlapping FOLLOW sets and not from state merging, LALR(1) also fails to resolve it. G is not LALR(1) either.
Why G is CLR(1):
CLR(1) uses full LR(1) items with precise lookahead sets per state. In CLR(1), the state where A → d• is the item will have the lookahead precisely as {a} in one state and {c} in another - they are separate states and never merged. This precise distinction resolves the conflict completely, making G a valid CLR(1) grammar.
Key takeaway - whenever a grammar is CLR(1) but not LALR(1), it means LALR(1) state merging causes a conflict that CLR(1) avoids by keeping those states separate.
Ques 10 GATE 2025 SET-2
Consider two grammars G1 and G2 with the production rules given below:
G1: S→if E then S|if E then S else S | a
E→b
G2: S→if E then S|M
M→if E then M else S | c
E→b
where if, then, else, a, b, c are the terminals.
Which of the following option(s) is/are CORRECT?
This question is a classic example of the dangling else problem in compiler design, and it tests whether you understand how grammar structure affects LL(1) parseability.
Analyzing G1:
G1 has the following productions for S:
S → if E then S | if E then S else S | a
The problem is immediately visible — both the first and second productions start with the terminal if. This means FIRST(if E then S) and FIRST(if E then S else S) both contain ''if'', causing a conflict in the LL(1) parsing table. An LL(1) parser uses just one token of lookahead to decide which production to apply, but here, seeing ''if'' alone doesn''t tell the parser which of the two ''if'' productions to choose.
This conflict makes G1 not LL(1). G1 is also ambiguous — the string "if b then if b then a else a" has two valid parse trees depending on which ''if'' the ''else'' is associated with. This is the textbook dangling else ambiguity.
Analyzing G2:
G2 cleverly resolves the dangling else problem by splitting S into two non-terminals:
S → if E then S | M
M → if E then M else S | c
Here, M represents a matched statement (every ''if'' has a corresponding ''else''), and S represents an unmatched statement (an ''if'' that may not have an ''else''). Let''s check the FIRST sets:
For S: FIRST(if E then S) = {if} and FIRST(M) = {if, c}. Wait — both contain ''if'', which would still be a conflict. However, looking more carefully, S → if E then S uses ''if'' to mean an unmatched if, while M → if E then M else S requires a matched if. The grammar design ensures the parser always associates an ''else'' with the nearest unmatched ''if'', resolving the ambiguity structurally.
In G2, no string has two different parse trees — the grammar is unambiguous. With proper FIRST/FOLLOW analysis, the parsing table for G2 has no conflicts, confirming G2 is LL(1).
Checking Option D — are both grammars ambiguous?
G1 is ambiguous (as shown above). G2 is not ambiguous — its design specifically eliminates the dangling else ambiguity by forcing the ''else'' to always match the nearest ''if''. So Option D is incorrect.
Ques 11 GATE 2025 SET-2
Consider the following statements:
(i) Address Resolution Protocol (ARP) provides a mapping from an IP address to the corresponding hardware (link-layer) address.
(ii) A single TCP segment from a sender S to a receiver R cannot carry both data from S to R and acknowledgement for a segment from R to S.
Which ONE of the following is CORRECT?
The correct answer is Option B - (i) is TRUE and (ii) is FALSE.
Statement (i) - ARP provides a mapping from IP address to hardware address: TRUE. ARP (Address Resolution Protocol) is specifically designed to resolve a 32-bit IPv4 address to its corresponding 48-bit MAC (hardware/link-layer) address on the same local network. A device broadcasts an ARP request, and the device with the matching IP replies with its MAC address.
Statement (ii) - A single TCP segment cannot carry both data and ACK: FALSE. TCP absolutely supports carrying both data and an acknowledgement in the same segment - this is called piggybacking. In a bidirectional TCP connection, when S sends data to R and also needs to acknowledge data received from R, it combines both into one segment. This is standard TCP behavior and improves network efficiency by reducing the number of segments transmitted.
So statement (i) is correct and statement (ii) is wrong - making Option B the answer.
Ques 12 GATE 2025 SET-2
Consider the routing protocols given in List I and the names given in List II:
List I
(i) Distance vector routing
(ii) Link state routing
List II
(a) Bellman-Ford
(b) Dijkstra
For matching of items in List I with those in List II, which ONE of the following options is CORRECT?
The correct answer is Option A - (i)-(a) and (ii)-(b).
Distance vector routing → Bellman-Ford: In distance vector routing, each router knows only its neighbors and the distances to them. It shares its routing table with neighbors periodically, and routes are computed iteratively using the Bellman-Ford algorithm. RIP (Routing Information Protocol) is the most well-known distance vector protocol.
Link state routing → Dijkstra: In link state routing, each router floods the entire network with information about its directly connected links. Every router builds a complete topology map and runs Dijkstra''s algorithm locally to compute the shortest paths to all destinations. OSPF (Open Shortest Path First) is the classic link state protocol.
Quick memory tip - Distance vector = Bellman-Ford (D-B), Link state = Dijkstra (L-D).
Ques 13 GATE 2025 SET-2
A machine receives an IPv4 datagram. The protocol field of the IPv4 header has the protocol number of a protocol X.
Which ONE of the following is NOT a possible candidate for X?
The correct answer is Option D - RIP (Routing Information Protocol).
The protocol field in the IPv4 header identifies which higher-layer protocol is directly carried in the IPv4 datagram. Let''s check each option:
ICMP (Option A): Has IPv4 protocol number 1. Directly encapsulated in IPv4. Valid candidate.
IGMP (Option B): Has IPv4 protocol number 2. Directly encapsulated in IPv4. Valid candidate.
OSPF (Option C): Has IPv4 protocol number 89. Directly encapsulated in IPv4. Valid candidate.
RIP (Option D): RIP does not have its own IPv4 protocol number. It runs over UDP (port 520), so the IPv4 protocol field would show 17 (UDP), not RIP. Not a valid candidate.
The key distinction — protocols like ICMP, IGMP, and OSPF are directly carried in IP and have assigned protocol numbers. RIP is an application-layer routing protocol that uses UDP as its transport.

Total Unique Visitors